D'Agostino's K-squared test
In statistics, D’Agostino’s K2 test is a goodness-of-fit measure of departure from normality, that is the test aims to establish whether or not the given sample comes from a normally distributed population. The test is based on transformations of the sample kurtosis and skewness, and has power only against the alternatives that the distribution is skewed and/or kurtic.
Contents |
Skewness and kurtosis
In the following, let { xi } denote a sample of n observations, g1 and g2 are the sample skewness and kurtosis, mj’s are the j-th sample central moments, and 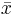 is the sample mean. (Note that quite frequently in the literature related to normality testing the skewness and kurtosis are denoted as √β1 and β2 respectively. Such notation is less convenient since for example √β1 can be a negative quantity).
is the sample mean. (Note that quite frequently in the literature related to normality testing the skewness and kurtosis are denoted as √β1 and β2 respectively. Such notation is less convenient since for example √β1 can be a negative quantity).
The sample skewness and kurtosis are defined as
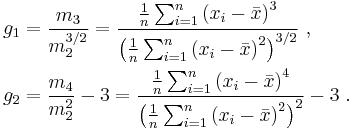
These quantities consistently estimate the theoretical skewness and kurtosis of the distribution. Moreover, if the sample indeed comes from a normal population, then the exact finite sample distributions of the skewness and kurtosis can themselves be analysed in terms of their means μ1, variances μ2, skewnesses γ1, and kurtoses γ2. This has been done by Pearson (1931), who derived the following expressions:
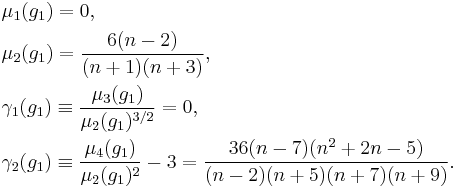
and

For example, a sample with size n = 1000 drawn from a normally distributed population can be expected to have a skewness of 0 ± 0.08 and a kurtosis of 0 ± 0.15, where the ± indicates the standard deviation.
Transformed sample skewness and kurtosis
The sample skewness g1 and kurtosis g2 are both asymptotically normal. However the rate of their convergence to the distribution limit is frustratingly slow, especially for g2. For example even with n = 5000 observations the sample kurtosis g2 has both the skewness and the kurtosis of approximately 0.3, which is not negligible. In order to remedy this situation, it has been suggested to transform the quantities g1 and g2 in a way that makes their distribution as close to standard normal as possible.
In particular, D’Agostino (1970) suggested the following transformation for sample skewness:

where constants α and δ are computed as
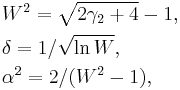
and where μ2 = μ2(g1) is the variance of g1, and γ2 = γ2(g1) is the kurtosis — the expressions given in the previous section.
Similarly, Anscombe & Glynn (1983) suggested a transformation for g2, which works reasonably well for sample sizes of 20 or greater:
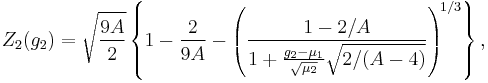
where

and μ1 = μ1(g2), μ2 = μ2(g2), γ1 = γ1(g2) are the quantities computed by Pearson.
Omnibus K2 statistic
Statistics Z1 and Z2 can be combined to produce an omnibus test, able to detect deviations from normality due to either skewness or kurtosis (D’Agostino, Belanger & D’Agostino 1990):

If the null hypothesis of normality is true, then K2 is approximately χ2-distributed with 2 degrees of freedom.
Note that the statistics g1, g2 are not independent, only uncorrelated. Therefore their transforms Z1, Z2 will be dependent also (Shenton & Bowman 1977), rendering the validity of χ2 approximation questionable. Simulations show that under the null hypothesis the K2 test statistic is characterized by
| expected value | standard deviation | 95% quantile | |
|---|---|---|---|
| n = 20 | 1.971 | 2.339 | 6.373 |
| n = 50 | 2.017 | 2.308 | 6.339 |
| n = 100 | 2.026 | 2.267 | 6.271 |
| n = 250 | 2.012 | 2.174 | 6.129 |
| n = 500 | 2.009 | 2.113 | 6.063 |
| n = 1000 | 2.000 | 2.062 | 6.038 |
| χ2(2) distribution | 2.000 | 2.000 | 5.991 |
References
- Anscombe, F.J.; Glynn, William J. (1983). "Distribution of the kurtosis statistic b2 for normal statistics". Biometrika 70 (1): 227–234. JSTOR 2335960.
- D’Agostino, Ralph B. (1970). "Transformation to normality of the null distribution of g1". Biometrika 57 (3): 679–681. JSTOR 2334794.
- D’Agostino, Ralph B.; Albert Belanger; Ralph B. D’Agostino, Jr (1990). "A suggestion for using powerful and informative tests of normality". The American Statistician 44 (4): 316–321. JSTOR 2684359. http://www.cee.mtu.edu/~vgriffis/CE%205620%20materials/CE5620%20Reading/DAgostino%20et%20al%20-%20normaility%20tests.pdf.
- Pearson, Egon S. (1931). "Note on tests for normality". Biometrika 22 (3/4): 423–424. JSTOR 2332104.
- Shenton, L.R.; Bowman, K.O. (1977). "A bivariate model for the distribution of √b1 and b2". Journal of the American Statistical Association 72 (357): 206–211. JSTOR 2286939.